Backoffice AI Agent 구축기 — RAG+MCP 기반 플레이스AI 특화 지식 검색 시스템
백오피스 문서 검색을 위해 RAG와 MCP 기반 지식 검색 에이전트를 구축했습니다.\n하이브리드 검색과 질의 정제로 응답 만족도와 운영 효율을 함께 높였습니다.
#RAG#MCP#검색
17700
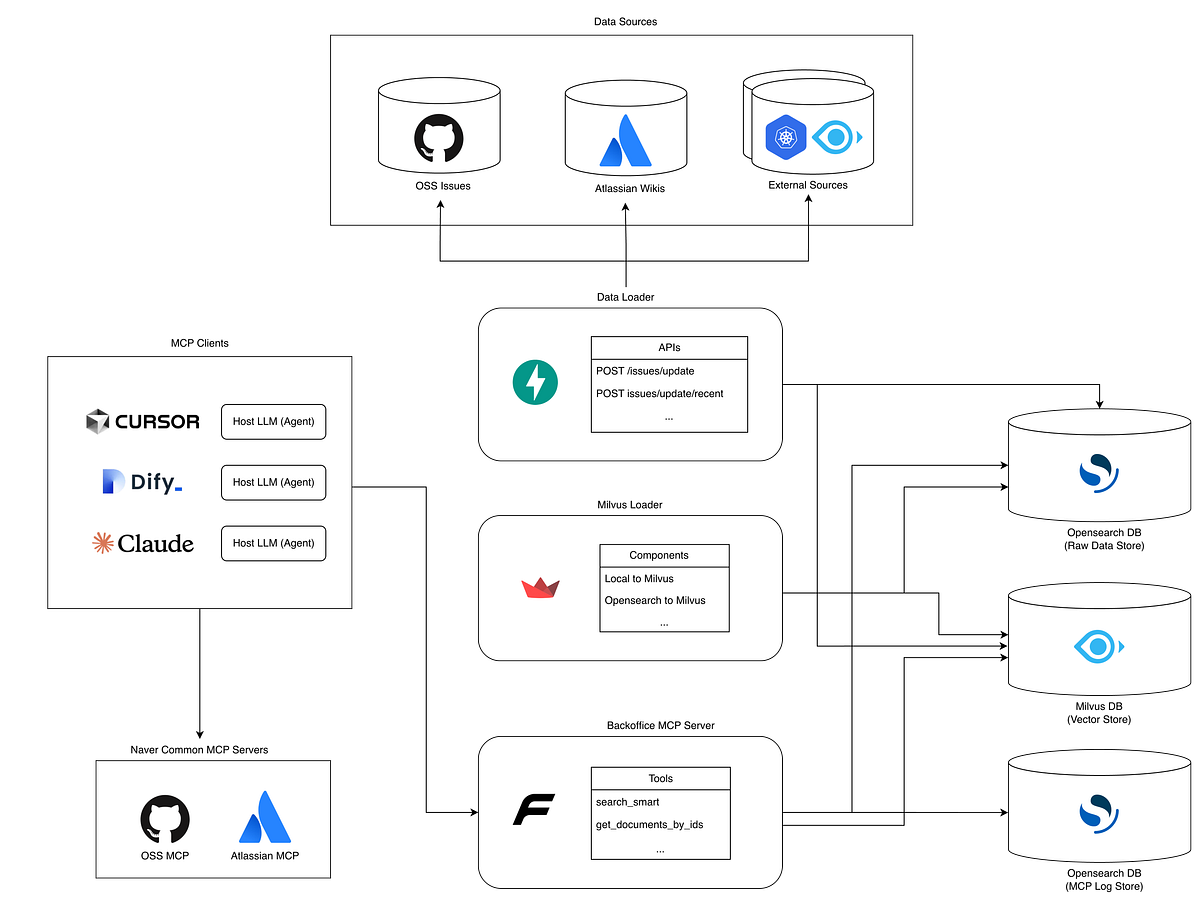

백오피스 문서 검색을 위해 RAG와 MCP 기반 지식 검색 에이전트를 구축했습니다.\n하이브리드 검색과 질의 정제로 응답 만족도와 운영 효율을 함께 높였습니다.
YARN 환경의 Trino 리소스를 재조정해 장비 증설 없이 가용 메모리를 늘리는 과정을 정리했습니다. AM Container와 RESERVED Resource를 고려해 Worker 중심으로 설정을 최적화했습니다.

네이버 지도 내비게이션 품질 향상을 위해 좁은 도로 탐지 모델을 개선한 사례를 소개했습니다. 수치지형도와 거리뷰 이미지를 활용해 더 정확한 도로 너비 판별 방식을 적용했습니다.

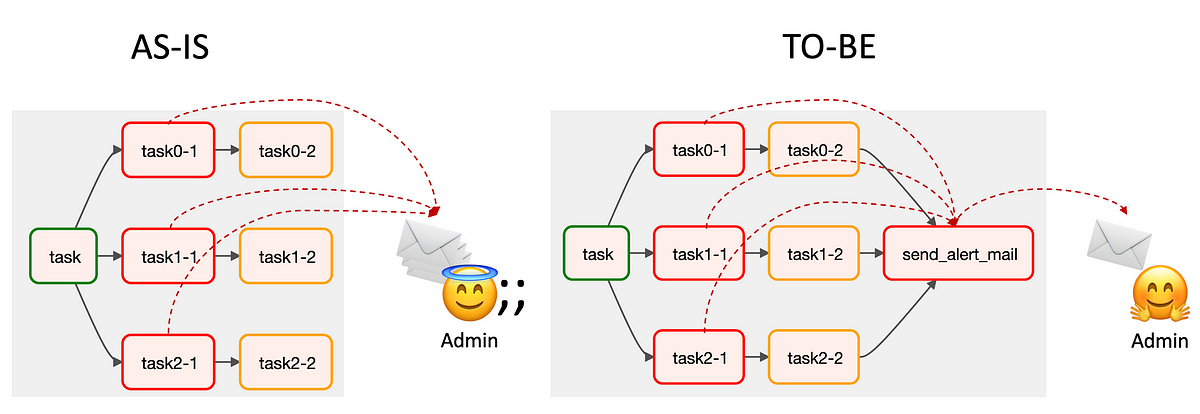
Airflow에서 동일 원인으로 반복 발송되는 Task 실패 알림을 하나로 통합하는 방법을 다루었습니다. DAG run의 Task Instance와 로그를 활용해 중복 메일 노이즈를 줄이는 구현을 소개했습니다.
Airflow 개발 환경을 Docker compose로 컨테이너화해 배포와 유사한 상태에서 실행·디버깅할 수 있게 구성했습니다. PyCharm 연동, Executor 분리, 설정 통합으로 개발 생산성과 관리 편의도 높였습니다.

태깅 파이프라인을 원본 저장, 로직 분리, write buffer로 재설계해 업데이트 부하를 줄였습니다. 운영툴 통합과 수동 태그 보존으로 관리성과 안정성도 함께 높였습니다.

NAVER GLACE AI 개발팀의 서비스 적용 사례와 운영 체계를 소개했습니다. 또한 PlaceLM을 중심으로 태그 추출과 서빙 효율 개선 방향을 설명했습니다.
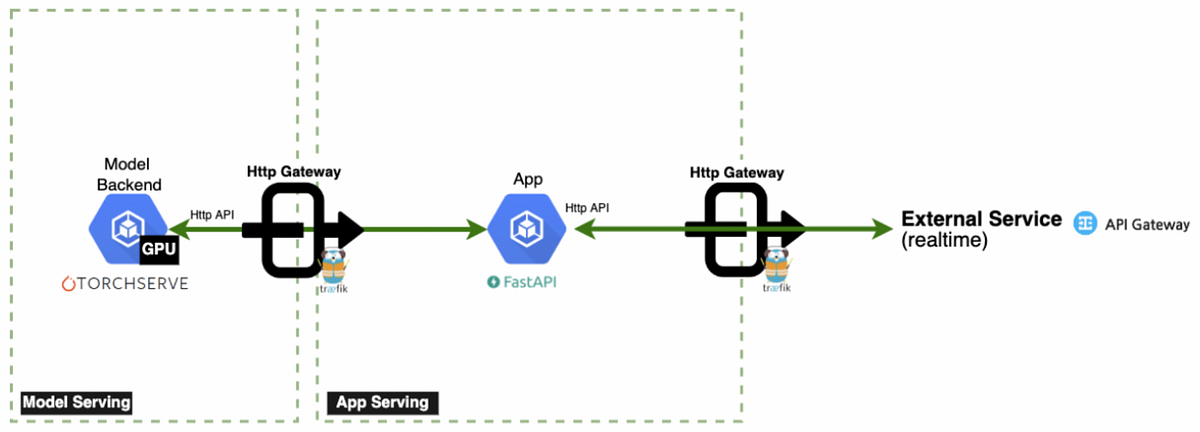
GPU 모델 서버를 CPU 서버로 전환하면서 성능 저하를 막기 위해 worker, thread, IPEX, KD를 함께 최적화했습니다. 그 결과 서비스 품질을 유지하며 GPU 자원을 절감했습니다.
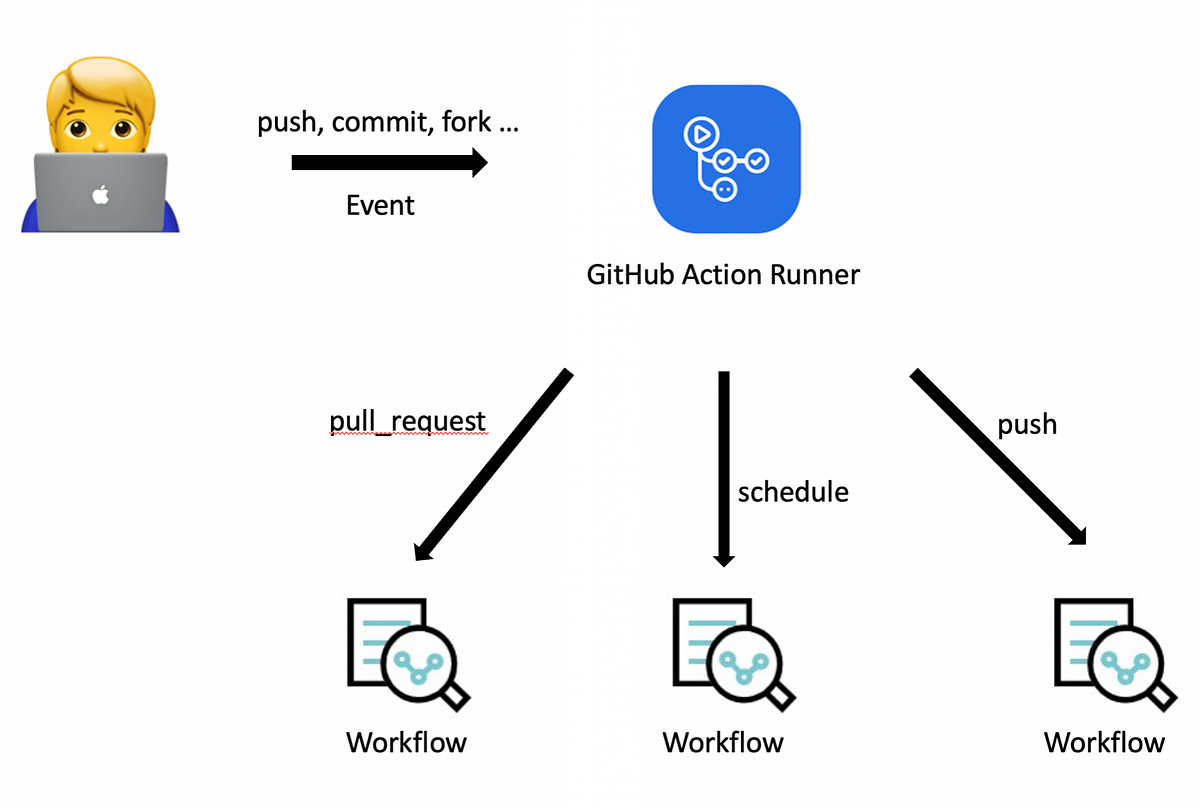
GitHub Actions로 PR 검사, 자동 승인, 코멘트 작성 같은 반복 작업을 자동화한 사례를 소개했습니다. 워크플로우, 컨텍스트, Marketplace 활용과 GitHub Enterprise 적용 시 유의점도 함께 정리했습니다.
MinIO를 아카이빙 스토리지로 도입하며 HA와 Failover 동작을 검증하고, 장애 레벨별 대응 기준을 정리했습니다. 또한 HDFS distcp와 Airflow로 Backup & Restore 체계를 구성해 DR 전략을 마련했습니다.

DataHub의 Protobuf nested message 주석 미표시 문제를 원인 분석 후 코드와 테스트로 수정했습니다. 오픈소스 기여 과정에서 Slack 커뮤니케이션과 Checkstyle 대응도 함께 경험했습니다.

네이버 GLACE AI 개발팀이 서비스에 적용하는 NLP·CV 모델과 전용 LLM PlaceLM을 소개했습니다. 또한 데이터 버전 관리, 모니터링, 무중단 배포 등 운영 체계도 함께 다뤘습니다.
Hive 사용량 통계를 수집해 하둡 플랫폼 운영 효율을 높인 개발 사례를 소개했습니다. 크롤링 한계를 로그 분석과 실시간 처리 구조로 개선하고 Iceberg 적재 방식도 조정했습니다.
